


بررسی GB300-NVL72 نشاندهنده یک انقلاب در زیرساختهای AI و محاسبات فوقپیشرفته است. این سیستم rack-scale با طراحی کاملاً مایعخنک شامل ۳۶ پردازنده Grace و ۷۲ GPU Blackwell Ultra که یک دیوار پردازشی عظیم را شکل میدهند. شبکه ارتباطی NVLink نسل پنجم با پهنایباند ۱۳۰ TB/s، این دستگاه را به یک GPU عظیم واحد تبدیل کرده است.
معماری پردازشی و شبکه سرعت بالا
در GB300 NVL72 ارتباط GPUها توسط NVLink نسل پنجم و NVSwitch انجام میشود. این ساختار امکان اتصال تا ۵۷۶ GPU با پهنایباند داخلی که به پتابایت میرسد را میدهد. هر GPU پهنایباند دوجهتی تا ۱.۸ TB/s دارد، معادل ۱۴ برابر سریعتر از PCIe Gen5. این سطح از مقیاسپذیری برای مدلهای AI با پارامترهای تریلیونی ضروری است.
عملکرد AI reasoning باورنکردنی
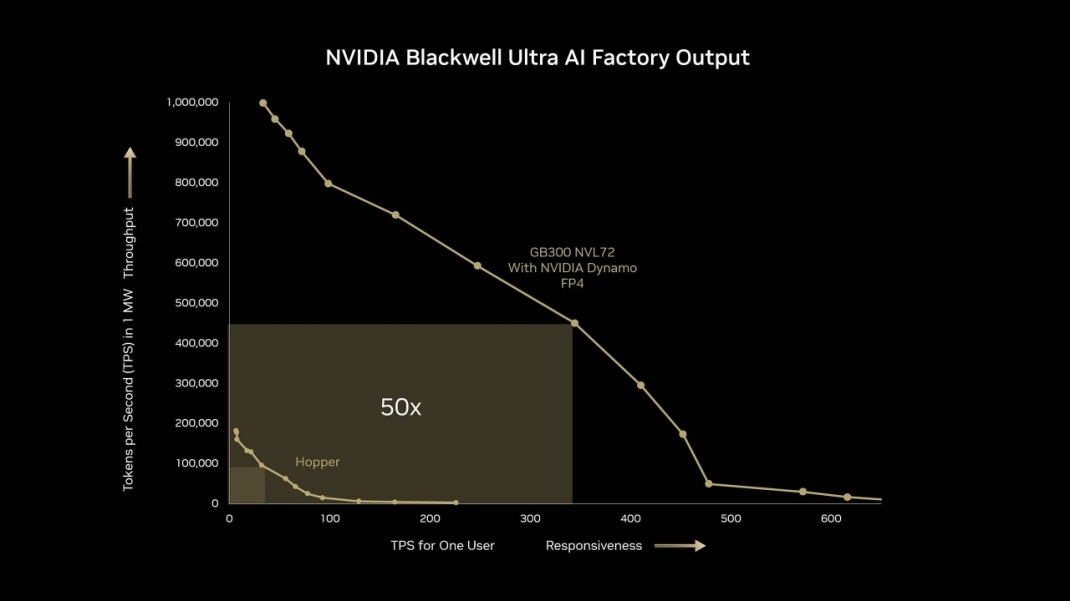
GB300 NVL72 به لطف Blackwell Ultra Tensor Cores با 2× شتاب attention-layer و حافظه HBM3e تا ۲۸۸ GB برای هر GPU، عملکرد AI reasoning را شگفتآور افزایش داده است. قدرت AI reasoning این زیرساخت برابر با 1.1 ExaFLOPS در FP4 است. مجموع عملکرد کلی دستگاه، همراه با عملکرد ۵۰× بیشتر در AI factory output نسبت به پلتفرمهای نسل Hopper است. نسبت TPS به کاربر ۱۰× بهتر و throughput بـر حسب هر مگاوات نیز ۵× ارتقا یافته است.
حافظه و پهنایباند فراگیر
سیستم GB300 NVL72 با ترکیب GPU و CPU، تا ۴۰ TB حافظه سریع (HBM3e + LPDDR5X) را در یک رک فراهم میکند. هر GPU دارای ۲۸۸ GB HBM3e و پهنایباند تا ۸ TB/s است. همچنین معماری Grace Blackwell Ultra Superchip پشتیبانی از Cache لایهبندیشده با ۱ TB حافظه یکپارچه فراهم میآورد.
شبکه و اتصال بهینه
با تجهیزات شبکه قدرتمندی چون ConnectX-8 SuperNIC با سرعت ۸۰۰ Gb/s، GB300 NVL72 توانایی ارتباط مؤثر با سایر کلاسترها و شبکههای ابری را دارد. سازگاری با Quantum-X800 InfiniBand و Spectrum-X Ethernet، عملکرد AI را بهینه میکند و هماهنگی برای multi-node inference را تسهیل میسازد.
مصرف انرژی هوشمند و پایداری
مکانیزمهای Power Smoothing مانند Power Cap، انرژی ذخیرهشده و Power Burner این اجازه را میدهد تا مصرف برق هنگام شروع و پایان بارهای محاسباتی بدون نوسان ناگهانی مدیریت شود. همچنین هدر دادن انرژی نیز به حداقل رسیده است تا سیستم با ثبات بالا کار کند.
کاربردها و استقرار واقعی
این سیستم در تستها و استقرارها، عملکردی تا 6.5× برتری در DeepSeek R1 inference نسبت به H100 نشان داده است. CoreWeave اولین ارائهدهنده cloud با GB300 NVL72 بود که با سوئیچینگ هوشمند و مدیریت rack-scale، عملکرد فوقالعادهای ارائه داد.
مقایسه با پلتفرمهای پیشین
| ویژگی | GB300 NVL72 | GB200 NVL72 | Hopper (H100) |
|---|---|---|---|
| GPUها | 72 Blackwell Ultra | Blackwell | H100 |
| شبکه NVLink | 130 TB/s | کمتر | کمتر |
| حافظه هر GPU | 288 GB HBM3e | 192 GB | 80 GB HBM3 |
| AI reasoning output | 50× نسبت به Hopper | 30× | baseline |
| مصرف انرژی | مدیریت هوشمند و مایعخنک | معمولی | هواخنک |
| کاربردها | AI reasoning، HPC، inference at scale | مشابه با کمتر | تکنولوژی پایه AI |

نتیجهگیری نهایی بررسی GB300 NVL72
بررسی GB300-NVL72 نشان داده است که این سیستم معنای واقعی AI factory درون یک رک است. ترکیب پردازندههای Grace و GPU Blackwell Ultra، شبکه عظیم NVLink، ظرفیت حافظهای بیسابقه، شبکه ارتباطی ۸۰۰ Gb/s، و پایداری در مصرف انرژی، GB300 NVL72 را به یکی از پیشرفتهترین پلتفرمها برای هوش مصنوعی، reasoning در مقیاس بزرگ و HPC تبدیل کرده است. این سیستم آیندهی پردازش هوشمند را پایهگذاری میکند و گزینهای غیر قابل رقابت در بازار AI factory خواهد بود.